本連載では過去3回にわたって、ニューラルネットワークおよびディープラーニングの理論的な側面を紹介してきた。最終回となる今回は、これまでの知識を前提に、ディープラーニングライブラリを使ったプログラム実装について解説する。
ディープラーニングの開発環境
実装の具体的な解説に入る前に、開発環境について簡単に触れておきたい。
現時点(2017年2月)では、NVIDIAのDIGITSなどGUIの開発環境もあるが、ディープラーニング開発用ライブラリを使ったカスタム開発が一般的である。プログラミング言語ごとにさまざまなライブラリが提供され、日々改善されている。新しいライブラリも継続的にリリースされており、ディープラーニングの進化の速さがうかがえる。
ライブラリが提供されている開発言語は、C++、Python、Javaなどであるが(図表1)、言語自体の人気もあってかPython用ライブラリが最も充実しており、インターネットや書籍などで得られる情報も多い。
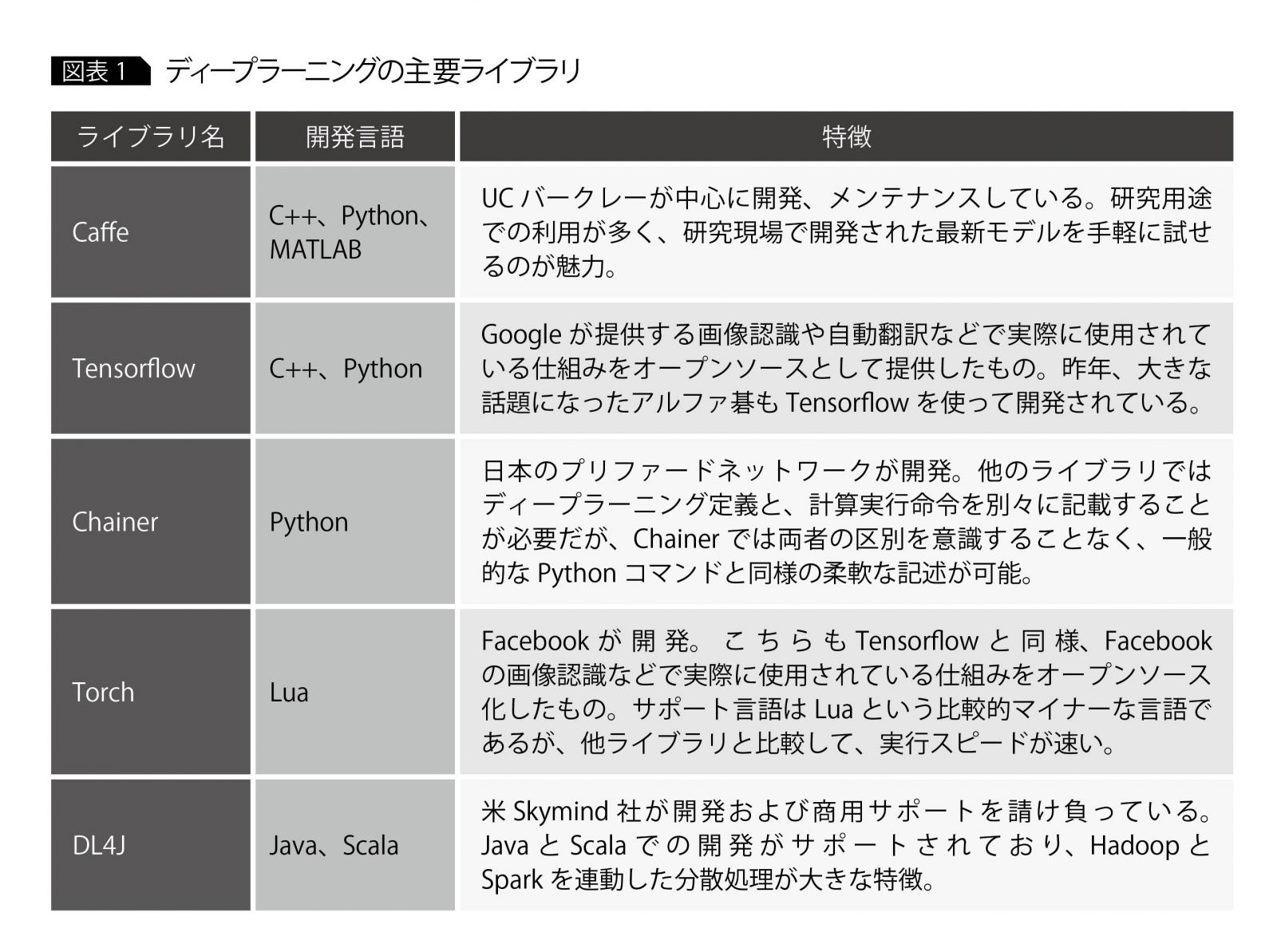
各ライブラリで提供されているAPIが異なるため、実装プログラムはライブラリごとにまったく違う。ただしライブラリが違っても、データロード、ネットワーク定義、学習など実装すべきロジックは共通している。そこで本稿では、Python言語とTensorflowライブラリという組み合わせを例に、サンプルコードを踏まえながら実装の流れを説明する。
なお開発時のハードウェアであるが、可能ならばGPUを搭載したマシンが望ましい。ディープラーニングの学習には、大量の行列演算が必要になるという特性上、CPUよりもGPUのほうが相性がよい。下記にあるNVIDIA社のベンチマークでも、ディープラーニングの学習では、GPUはCPUに比べて10倍以上のパフォーマンスが出ると報告されている。
SPEED UP TRAINING WITH GPU-ACCELERATED TENSORFLOW
http://www.nvidia.com/object/gpu-accelerated-applications-tensorflow-benchmarks.html
開発するネットワークの全体像
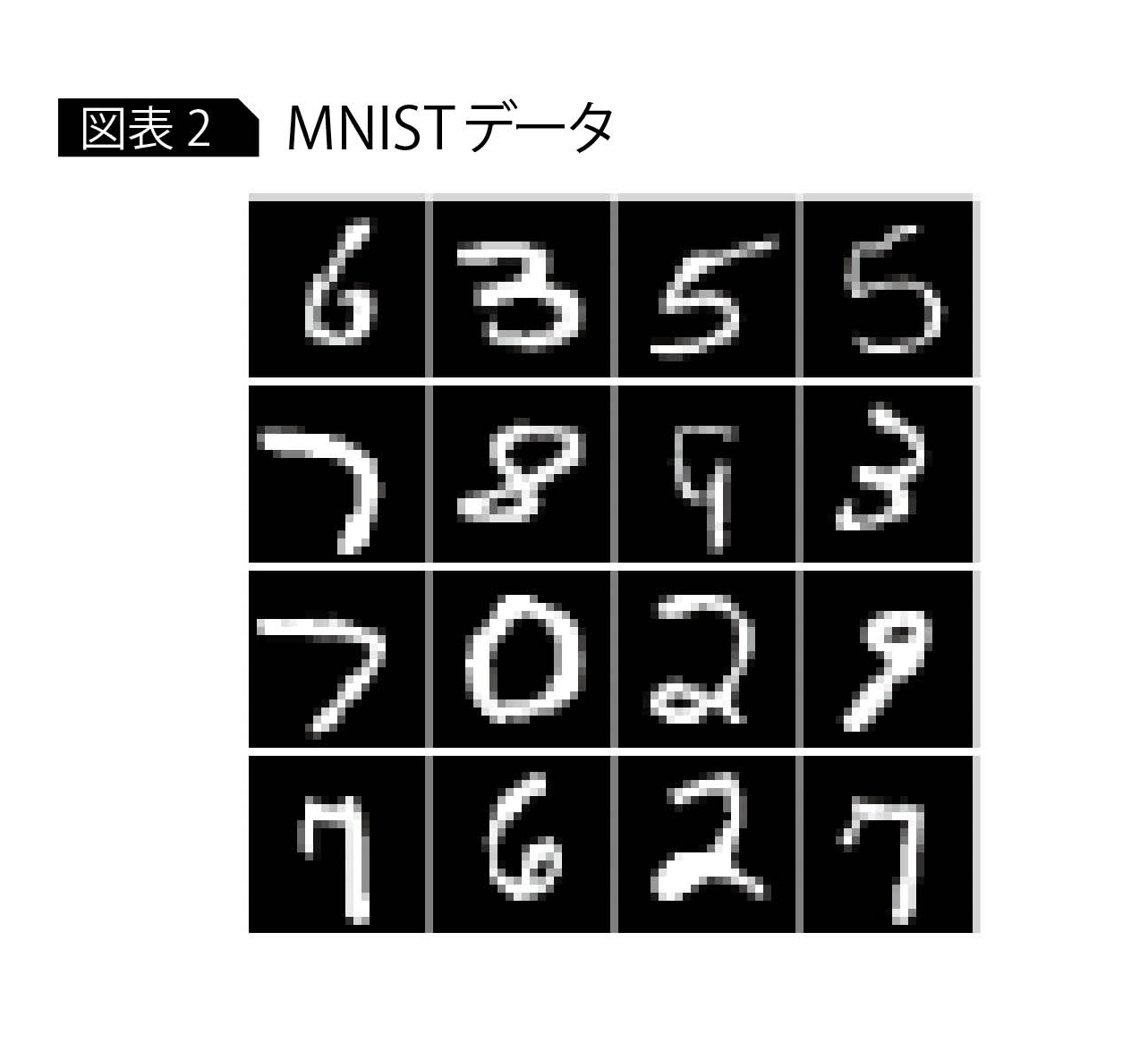
今回は題材として、MNISTと呼ばれる手書き数字の画像データセット(http://yann.lecun.com/exdb/mnist/)を用い、数字ごとに分類する畳み込みネットワークを開発する(畳み込みネットワークの詳細については連載第2回を参照)。
このデータは、28×28ピクセルのグレースケール画像であり(図表2)、学習用データとテストデータがそれぞれ用意されている。この学習用データを使ってネットワークの学習を行い、テストデータで学習済みネットワークの精度を評価する。
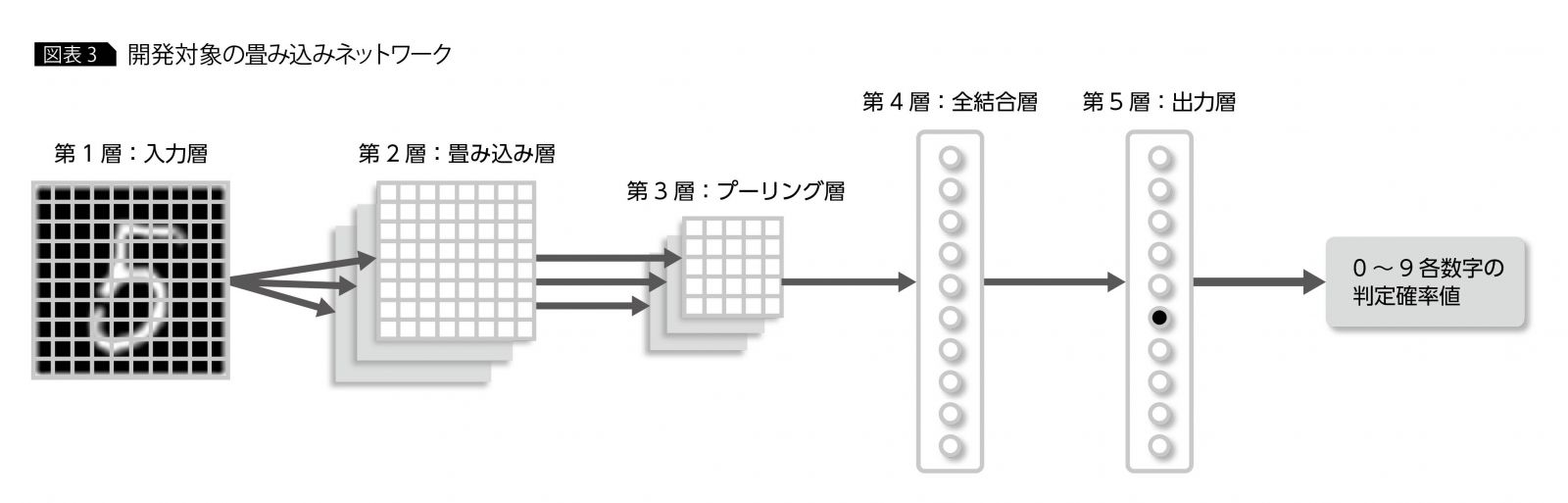
ネットワーク全体の入出力であるが、入力値として各手書き文字画像の28×28のピクセル値を受け取り、出力値としてその画像の0~9の各数字の判定確率値を出力する。入出力を含めたネットワーク全体の層構造は、図表3のとおりである。
これ以降、実装のステップごとにコードを紹介していくが、最後にすべてまとめて実行できるように記述しておく。実際に試す場合は、下記のURLの内容に沿って、Tensorflowを事前に導入しておく必要がある。
Tensorflow – Installing TensorFlow
https://www.tensorflow.org/install/
またソースコードについては誌面の都合上、要点のみを記述する。APIの詳しい仕様は、Tensorflowのマニュアルを参照されたい。
Tensorflow – API Documentation
https://www.tensorflow.org/api_docs/
実装の流れ
実装の流れは大きく、「1 畳み込みネットワークの定義」と「2 学習」という2つのフェーズに分けられる。
1はネットワーク構造を定義するフェーズである。以下に記載する「必須モジュールおよびデータのロード」「入力層の定義」「畳み込み層とプーリング層の定義」「全結合層と出力層の定義」がそれにあたる。ここでは、Tensorflowを使ってネットワーク構造の定義のみを実行しており、学習などの具体的な計算は実施しない。
2はデータを使って、1で定義した畳み込みネットワークに手書き文字を学習させるフェーズである。以下に記載する「誤差関数とOptimizeの定義」「畳み込みネットワークの学習」がそれにあたる。
それぞれを詳しく解説し、最後に1と2を実装したコードを実行して、データによる学習を通じて手書き文字の判別精度が上がっていく様子を見てみよう。
必須モジュールおよび
データのロード
最初に、必要なモジュールをロードする(図表4)。

1行目は、科学技術計算やデータ分析などでよく使われるnumpyというモジュールをロードしている。このモジュールは配列形式(numpyアレイと呼ばれる)でデータを格納し、その形式でさまざまな数理計算を実行できる。2行目は、ディープラーニングライブラリのtensorflowをロードしている。
次に、データをロードする(図表5)。Tensorflowには、手書き文字データセットのMNISTをダウンロードする関数が用意されているので、今回はそれを利用する。

ダウンロードが始まると、図表6のようなメッセージが出力される。ダウンロードが終了すると、カレントディレクトリに「MNIST_data」というディレクトリが作成され、MNISTデータが保存される。

図表5のmnistオブジェクトはすべてのデータセットを指すので、これを訓練データと訓練ラベル、テストデータとテストラベルに分割する。ちなみにラベルとは正解のことで、たとえば手書き文字0のラベルは1個目だけが1で、残りの9個はすべて0の配列[1, 0, 0, 0, 0, 0, 0, 0, 0, 0]で与えられ、同様に5のラベルは[0, 0, 0, 0, 0, 1, 0, 0, 0, 0]で与えられる。
図表7の処理によって、データは以下のように分割される。
x_train:訓練データ
y_train:訓練ラベル
x_test:テストデータ
y_test:テストラベル

ここで、訓練データx_trainの内容を確認してみよう(図表8)。

x_train内のデータ数は5万5000である。x_trainの中身を確認すると、[0. 0. 0. …, 0. 0. 0.]という配列が繰り返し表示されていることに気づく。1つの[0. 0. 0. …, 0. 0. 0.]が、1枚の手書き文字画像で、x_trainには5万5000個が格納されている。このままでは省略されてわかりにくいので、x_trainの1枚目の手書き文字データを確認すると、図表9になる。
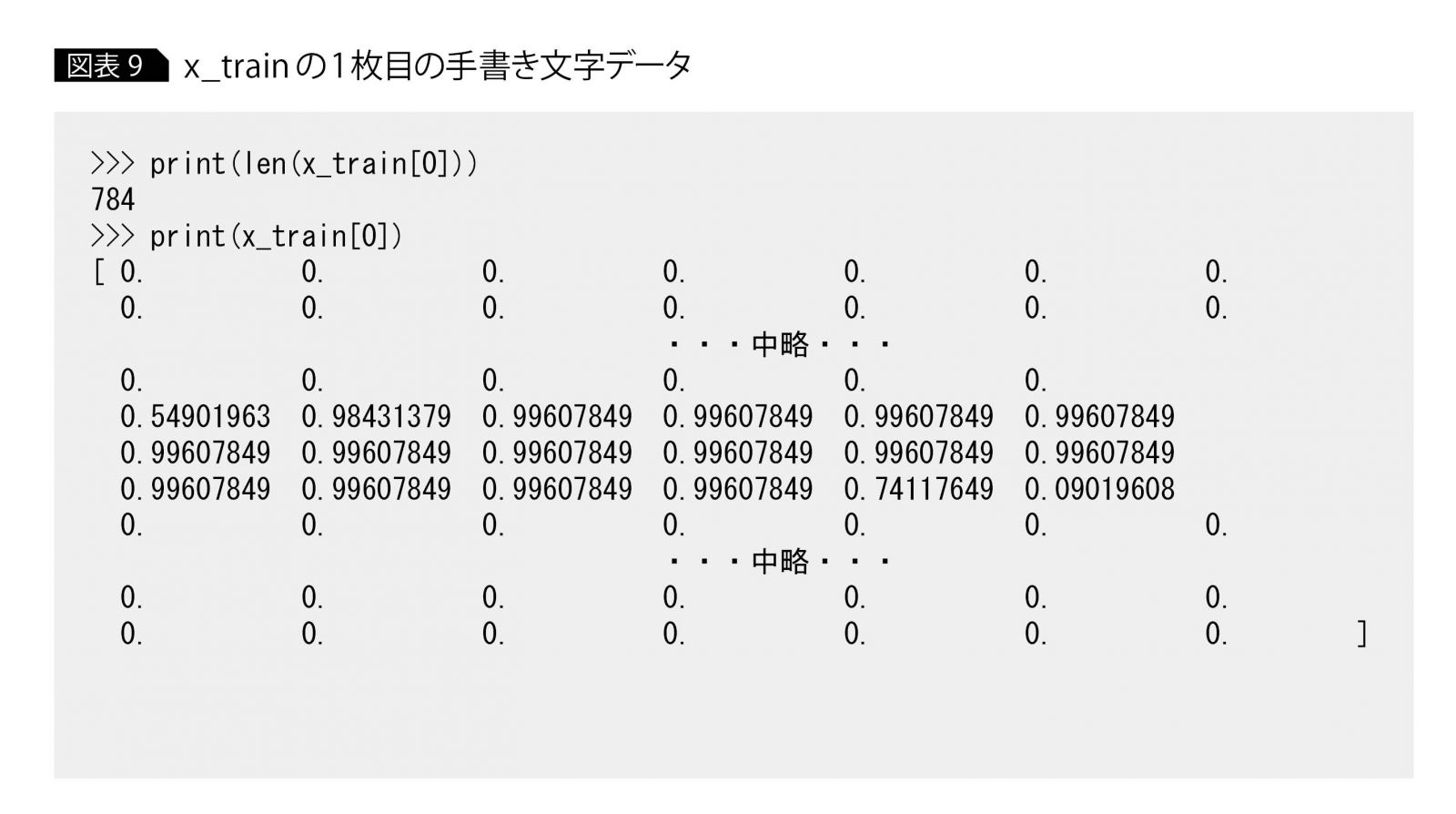
1枚目のデータx_train[0]のサイズは784とある。これは、28×28(=784)のサイズの画像データを、1次元配列として保存しているためである。
データx_train[0]の中身を確認すると、各要素は0?1の値であるとわかる。通常、グレースケールの画像データは各ピクセル値が0?255の値をとるが、このスケールではディープラーニングで扱いにくいので、0?1の値に正規化することが多い。今回は、Tensorflowのread_data_sets関数がそこまでの処理を実行する。
次に、訓練ラベルy_trainの内容を確認する(図表10)。
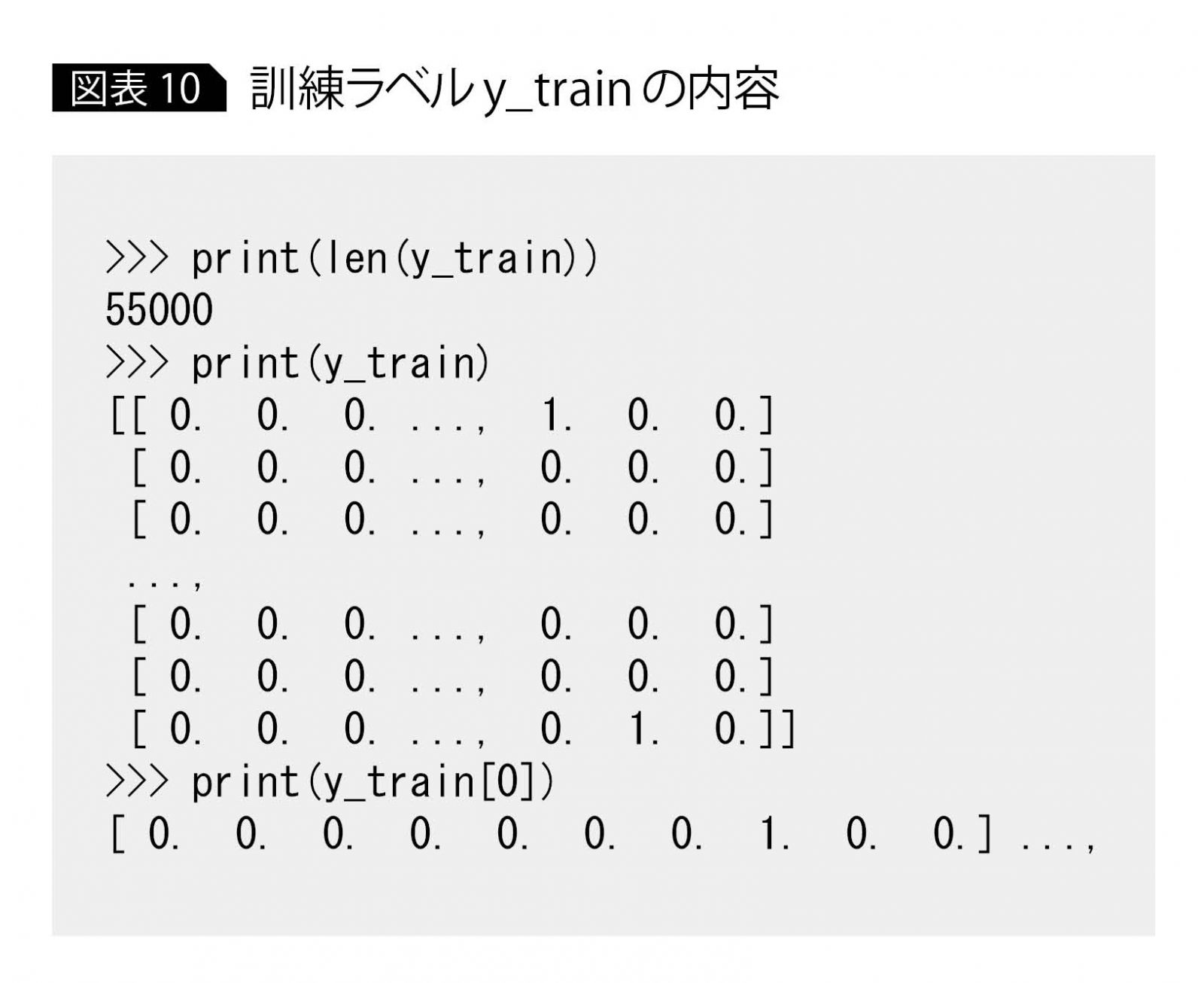
y_trainのデータサイズもx_trainと同じく5万5000個であり、この1つ1つがx_trainの各手書き文字データの正解ラベルとなっている。
上記の出力結果を見ると、y_trainの1つ目のデータy_train[0]は、8個目が1で、残りはすべて0の要素数10の配列となっている。これは7を表すため、先ほど中身を確認したx_train[0]は7の手書き文字を表すことになる。
なお、x_test、y_testもそれぞれx_train、y_trainと構造は同じだが、データ数が1万で構成されている(図表11)。

入力層の定義
ここから畳み込みネットワークを定義する。最初に、データの入力ポイントとなる入力層を定義する。
Tensorflowでは、x_trainなどの配列データを直接扱えない。そのため、Tensorflowでデータを表す関数「placeholder」を使ってネットワークを定義してから、実行時にplaceholderにデータを代入するというステップになる(図表12)。

1行目で、手書き文字データx_train、x_test用のplaceholderであるxを定義している。引数を詳しく見ると、最初にtf.float32とあるが、これは代入するデータの型が32bitのfloat型であることを表している。
次のshapeでは、データの形式を指定する。shape=[None, 28, 28]とあるが、Noneは任意の数を意味するので、これは28×28の形式の配列(手書き文字画像のサイズ)を任意のデータ数だけ格納できることを表す。
2行目では、xの形式変換を実行している。reshapeの引数[-1,28,28,1]で注目すべきは、最後の1である([-1, 28, 28]は[None, 28, 28]と同じ意味)。この1は画像のチャネル数を表している。今回はグレーケースの画像を扱うため、ここは1となる。カラー画像を扱う場合はRGBの3チャネルとなるので、3を指定する。
厳密には入力層の定義ではないが、ラベルy_train、y_testを格納するplaceholderもここで定義する。ラベルは要素数10の配列であるため、shape=[None, 10]と指定する。
あとで、x_imageに手書き文字データであるx_train、x_testを代入する必要があるが、x_train、x_testは要素数784の1次元配列なので、x_imageの28×28の2次元形式と合致しない。そのため図表13のように、x_trainとx_testの各データをx_imageと同じ形式28×28に合わせる。

畳み込み層と
プーリング層の定義
ここから、畳み込み層とプーリング層を定義する。
層定義の前に、コードの簡略化のため、学習対象の重み変数およびバイアス変数を初期化する関数を定義しておく(図表14)。ここではまだ関数を定義しているだけで、重み・バイアス変数の生成は行っていない。

重み変数の定義がweight_variableで、バイアス変数の定義がbias_variableである。戻り値に注目すると、ともにtf.Variable(initial)となっている。このtf.Variableは、データによる学習対象となる変数を表している。引数のinitialは初期値で、学習を繰り返すごとにinitialで指定した値から、学習内容に適した値にチューニングされていく。
また畳み込み層とプーリング層の定義も、関数化しておく(図表15)。

畳み込み層は、tf.nn.conv2dという関数で定義される。strides=[1, 1, 1, 1]の2つ目と3つ目の値は、局所受容野の移動量を意味している。ここでは、縦・横ともに1方向での移動を指定している。
一方、プーリング層はtf.nn.max_pool関数で定義される。ksize=[1, 2, 2, 1]の2つ目と3つ目の値は、プーリング層の1ニューロンと接続される畳み込み層の領域を表し、ここではともに2と指定されているため、畳み込み層の2×2個のニューロンがプーリング層の1ニューロンと接続されることになる。
プーリング層のstridesも、conv2d関数と同様の意味があり、畳み込み層の領域を縦方向に2ずつ、横方向にも2ずつ移動させながらプーリング層の1ニューロンと接続していく。
このように必要な関数を定義したら、次に畳み込み層とプーリング層を定義しよう。先ほど定義した関数を使うと、図表16のように簡単に記述できる。1~3行目が畳み込み層、最後の行がプーリング層の定義である。

W_conv1とb_conv1で、畳み込み層の重みとバイアスを定義している。
3行目のh_conv1では、入力層のx_imageをconv2dの畳み込み層関数で処理したあと、活性化関数tf.nn.reluで変換している。
最後の行のh_pool1には、畳み込み層からの出力h_pool1をプーリング層で処理した値を設定している。
ここで、畳み込み層の重みW_conv1の引数[4, 4, 1, 32]について説明しておこう。
最初の4, 4は、局所受容野のサイズである。次の1は入力層のチャネルで、手書き文字画像はグレースケールなので、チャネル数1となる。最後の32は畳み込み層のチャネル数である。このチャネル数は、畳み込み層が画像分類する際の手がかりにするフィルタ(小さい画像パターン)数となる。
全結合層と出力層の定義
次に、後続の全結合層の定義を行う(図表17)。

全結合層の処理を定義しているのは、4行目のh_fc1である。前段のプーリング層出力を1次元に変換したh_pool1_flat(プーリング層は画像と同様、縦・横の次元をもつが、全結合層は1次元で定義される)と1~2行目で定義した重み、バイアスを使った計算結果を活性化関数reluで処理している。
最後の2行は、ドロップアウトと呼ばれる処理を実装している。この処理は、学習時にあえて全結合層のニューロン数の一部のみを使うことで(全結合層ニューロン80のうち40程度)、学習データのみを高精度に判別し、テストデータの判別が苦手なモデルを生成する「過学習」という現象を防ぐ。このドロップアウト処理を入れた出力が、h_fc1_dropとなる。
そして、最後が出力層である(図表18)。出力層の定義は最終行y_convで、ドロップアウト処理をしたh_fc1_dropに重み、バイアス計算を施したあと、tf.nn.softmaxという関数で変換している。

このsoftmaxにより、10個の0?1の値がy_convの値として出力される。この10個の値は、それぞれ0~9までの手書き文字の確率を表現する。なお、y_convの10個の出力値は合計して1になるように計算される。
誤差関数とOptimizerの定義
ここから学習フェーズの実装である。最初に、誤差関数とOptimizerと言われるオブジェクトを定義する。
誤差関数とは、畳み込みネットワークからの出力値とラベルとの誤差を計算する関数で、この誤差関数を小さくするようにネットワークの重み変数とバイアス変数が学習される。
一方のOptimizerは、上記の学習アルゴリズムを実装したもの(具体的には、連載第2回で解説した勾配降下法のようなもの)である。いくつか種類があるが、ここではAdamと呼ばれるOptimizerを使用する(図表19)。

1行目が誤差関数の定義である。今回は0~9までの分類問題なので、クロスエントロピーと呼ばれる関数を実装している。
2行目は、tf.train.AdamOptimizerで勾配降下法を改良したAdamアルゴリズムで学習するように構成される。後ろのminimize(cross_entropy)は、1行目で定義した誤差関数が小さくなるように、重み変数とバイアス変数を調整することを示す。
AdamOptimizerの引数1e-4(0.0001)は学習率と呼ばれ、学習時の最も基本的なパラメータである。時間をかけてもネットワークの学習がうまく進まない場合は、最初にこのパラメータをチューニングするとよい。
さらに学習したネットワークの精度を評価するために、図表20のように2つの関数を定義しておく。

1行目はデータを畳み込みネットワークに投入したときの出力と、そのデータのラベルが合致しているかを確認する関数である。
2行目は、1行目の関数を用いて、投入データとラベルが何%合致しているかを計算する式を定義している。
畳み込みネットワークの学習
ここから、いよいよネットワークの学習に移る。最初に、いくつかの変数とオブジェクトを定義する(図表21)。

学習は5万5000のデータをすべて使って行うが、このすべてを使って誤差関数計算と重み・バイアス変数をチューニングすると計算量も多く、かなりの時間を要する。そのため、いくつかのデータセットに分割して、そのセットごとにチューニングする場合が多い。
1行目の32は、このデータセット1つ当たりに含まれるデータ数を意味し、バッチサイズと呼ばれる。今回はバッチサイズが32であるため、32データごとに変数のチューニングを実施することになる。
また変数のチューニングは、データを使って少しずつ値を変化させて行うので、適切な値に達するために、5万5000のデータを何度も繰り返し使う必要がある。この繰り返し回数はエポック数と呼ばれ、ここでは2行目のepoch_num = 10 として定義されている。
3行目は、Tensorflowの学習時に必要となるセッションと呼ばれるオブジェクトである。Tensorflowでは、ネットワーク定義と実行(値出力、学習実施など)は分けてコーディングする仕様になっており、事前に行ったネットワーク定義を使って学習計算を実行する際には、このセッションを生成する必要がある。
最後の行は、ネットワーク定義に含まれる全変数の初期化である。学習実行前には必ず実行しておく必要がある。
学習実行と精度計算をまとめて記述すると、図表22のようになる。
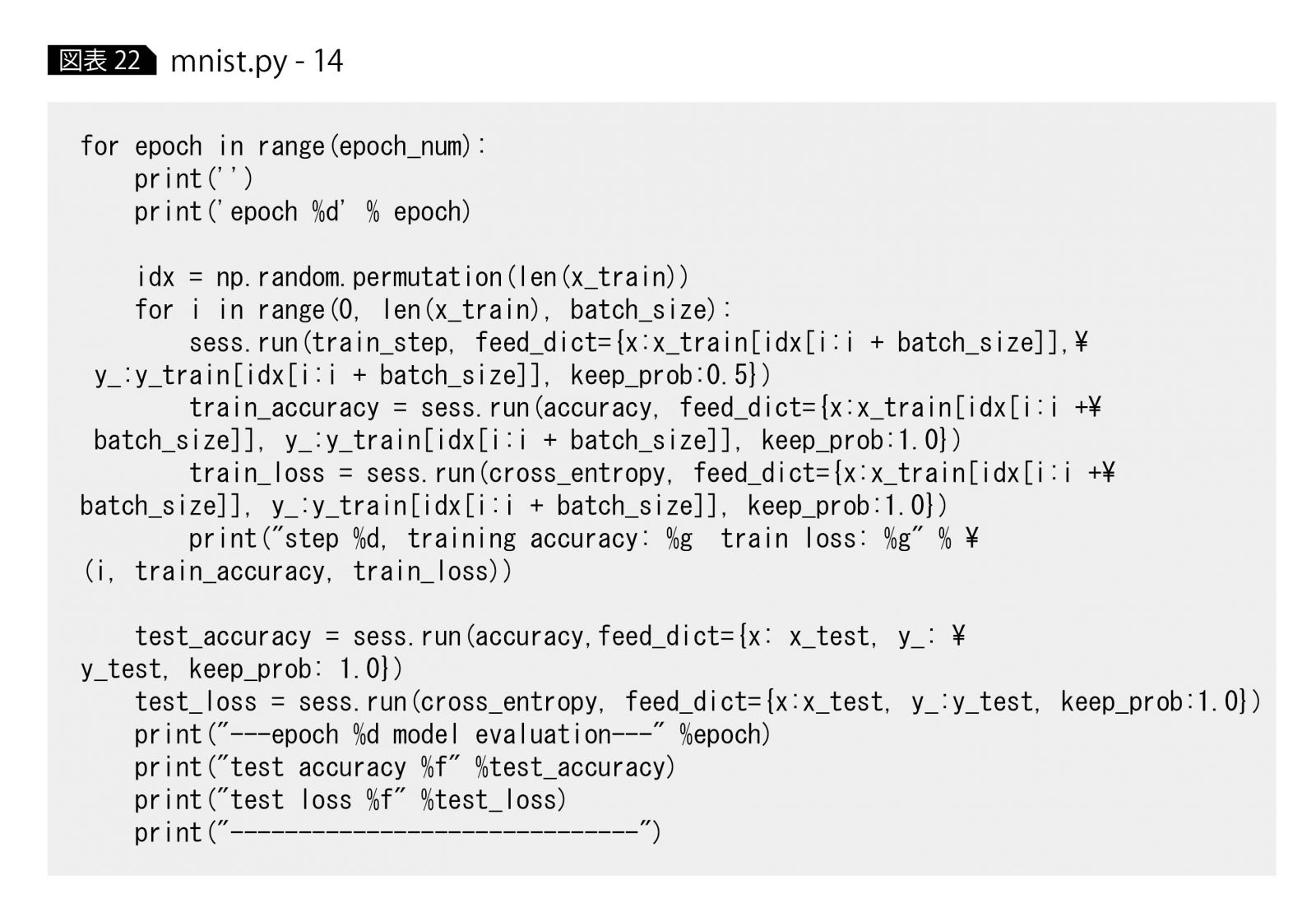
まず全体を見ると、epoch_num回数のループを実行する処理になっている。これは、先ほど説明した全データをエポック数回繰り返して学習する処理に相当する。
5行目に2つ目のfor文がある。こちらも先ほど説明した部分で、バッチサイズごとに重み・バイアスチューニングを実行する処理である。
最も重要なのは、6行目sess.run(train_step, feed_dict={x:…, y_:…, keep_prob:…})である。このコードは、図表19で定義した学習方法train_stepに従って、実際に重み・バイアス変数のチューニングを実施することを意味している。
このとき、feed_dict={x:…, y_:…, keep_prob:…}という引数が、x、y_、keep_probという事前定義したplaceholderに実際のデータを代入する操作を行っている。
なおここでkeep_prob:0.5は、図表17で説明したドロップアウトで、過学習を防ぐために全結合層のニューロン数のうちの0.5(半分)だけを使って学習している。
残りの処理(train_accuracy、train_loss、test_accuracy、test_loss)はすべて、学習された時点での畳み込みネットワークの精度を評価し、それぞれ以下の値を計算する。
train_accuray:x_trainに対する畳み込みネットワーク出力の正解率
train_loss:x_trainに対する畳み込みネットワーク出力と正解ラベルy_trainとの誤差値
test_accuray:x_testに対する畳み込みネットワーク出力の正解率
test_loss:x_testに対する畳み込みネットワーク出力と正解ラベルy_testとの誤差値
コードの実行
以上でコードが完成したので、実際に実行してみよう。図表4から図表22のなかで「mnist.py-XX」(XXは数字)の見出しのコードを1つのファイルにまとめ、”mnist.py”という名前で保存し、Tensorflowがインストールされた環境で、コマンドpython mnist.pyを実行する。
すると、図表23のように出力される。training accuracy、train lossはそれぞれ学習データに対する精度および誤差である。バッチサイズ32ごとに重み・バイアス変数がチューニングされ、精度と誤差が変化していくのがわかる。エポック終了時には、下記のように出力される。

—epoch 0 model evaluation—
test accuracy 0.917600
test loss 0.307069
これは、1エポックの全データ(5万5000)で学習したネットワークに対して、テストデータを使って精度評価した結果である。test accuracyはテスト精度であり、テストデータに対する学習済みネットワークの判別結果が、テストラベル(正解)とどれくらいの割合で合致しているかを表している。すでに1エポック目(epoch = 0)で91.7%と、かなり高い割合で正解している。
このテスト精度はエポックが増えるごとに向上し、今回の実行では10エポック目(epoch = 9)で、97.77%にまで達している。
—epoch 9 model evaluation—
test accuracy 0.977700
test loss 0.068471
これで1万個のテストデータのうち、9777個までを正しく判別する畳み込みネットワークが完成したことになる。
*
今回は、Tensorflowを使ってディープラーニングのプログラム実装の流れを説明した。ただし、プロジェクトなどで実際にシステム実装する際には、学習したディープラーニングモデルの保存・ロードのような運用面や、精度が出ない場合のチューニングポイントなど、追加で考慮すべきことが多々存在する。
Tensorflowをはじめとする各種ライブラリのチュートリアルには、そうしたトピックスも記述されているので、必要に応じて参照されたい。
・・・・・・・・
著者|植田 佳明 氏
日本アイ・ビー・エム システムズ・エンジニアリング株式会社
アナリティクス・ソリューション
アドバイザリーITスペシャリスト

2001年、日本IBM入社。2005年に日本アイ・ビー・エム システムズ・エンジニアリングに出向し、当初はIAサーバー基盤、WebSphere Application Server関連のプロジェクトや技術サポートを担当。2012年よりSPSSを中心としたアナリティクス製品のサポートやデータ分析プロジェクトに従事し、近年ではWatson・ディープラーニングといった人工知能、コグニティブ関連の活動にも携わっている。
[IS magazine No.15(2017年7月)掲載]
・・・・・・・・
連載 ディープラーニング入門 全4回 CONTENTS
第3回 再帰型ニューラルネットワークの「基礎の基礎」を理解する
・・・・・・・・







